개요
저번 시간에는 데이터를 저장하는 법을 배웠고, 이번 시간에는 저장한 데이터를 조작하는 방법을 배우겠다.
목차
< 1 > 데이터 조작 장치
1. 데이터 조작 시스템
2. CPU 구조
3. CPU 명령어
4. 명령어 실행과정
5. 제어기
< 2 > 데이터 조작 SW
1. 컴파일러와 링커
2. 운영체제
< 3 > 데이터 조작 연산
1. 마스킹
2. 쉬프트
< 4 > 데이터 조작 통신
1. 사상 I/O
2. 핸드셰이킹
3. 직렬 & 병렬 전송
1. 데이터 조작 장치
1. 데이터 조작 시스템

데이터의 조작 장치는 일단 대표적으로 시스템 버스와 I/O 버스가 있다.
시스템 버스는 CPU와 메모리가 서로 데이터, 주소, 제어신호를 주고 받을 수 있게 하는 통로 역할을 합니다.
시스템 버스는 제어버스, 주소버스, 데이터버스 세가지로 나뉘며 데이터 버스에서는 데이터, 주소버스에서는 주소 제어버스에서는 명령어를 전달하는 기능을 합니다.
메모리의 종류로는 온 칩 캐시 메모리, 오프 칩 캐시 메모리, 메모리 (RAM)이 있습니다.
온 칩 캐시 메모리와 오프 칩 캐시 메모리의 차이는 CPU의 안에 있느냐 밖에 있느냐의 차이 입니다.
I/O 버스는 CPU와 입출력 장치가 서로 데이터, 제어신호를 주고 받을 수 있게하는 통로 역할을 합니다.
입출력 장치로는 아주 다양하게 있습니다. 유의해야할 것은 하드 디스크, USB, CD-ROM도 입출력 장치라는 것입니다.
그리고 기본적인 입출력 장치들은, 키보드, 디스플레이, 마우스, 스캐너, 프린터, 네트워크 장치 등이 있습니다.
마지막으로 I/O 버스의 데이터와 제어신호를 CPU에게 보내는 방법은
I/O 컨트롤러와 컨트롤 Circuit과 연결되는 것이다. 그 두개는 시스템 버스와 연결되고 시스템 버스는 CPU와 연결된다.
이런 식으로 꼬리에 꼬리를 물어서 결국 데이터와 제어신호를 주고받을 수 있게 된다.
I/O 컨트롤러는 데이터를, Control Circuit는 제어신호를 담당한다.
이제 CPU의 종류에 대해서 알아보겠다.
먼저, RISC가 있다.
Reduced Instruction Set Computer라는 뜻이다.
기본적이고 잘 정의된 동작을 하는 명령들만 가진 CPU 설계 방식이다.
그러니까 많은 수의 레지스터와 명령어 해석기를 중심으로 회로가 구성된 단순한 설계다.
이로 인해, 명령 형식과 수행사이클이 일정하다.
그래서 명령어 길이가 제약되고, 점프할 수 있는 주소의 범위가 제한된다.
그리고 단순하다 보니까 한번에 한 내용만을 처리 할 수 있어서
같은 내용을 처리하는 데에 CISC보다 더 많은 코드 용량이 필요하다.
유명한 제조사로는 ARM이 있다.
그다음 CISC가 있다.
Complex Instruction set Computer라는 뜻이다.
기본적이고 잘 정의된 동작을 하는 명령도 가지고 복잡한 동작을 하는 명령도 가진다.
명령어의 길이와 수행 사이클이 다양하고 여러 일을 한 명령로 처리할 수 있다.
복잡한 SW에 잘 대처할 수 있다.
참고로 복잡한 명령어를 해석하기 위해 ROM에 저장된 마이크로 코드를 사용한다.
유명한 제조사로는 인텔과 AMD가 있다.
2. CPU 구조

이제 시스템 버스 쪽 장치들의 내부에 대해서 살펴볼거야.
CPU는 5가지의 레지스터, 프로그램 카운터, 실행 유닛이 있다.
레지스터 5가지는 명령어 레지스터, 메모리 레지스터 2개, 입출력 레지스터 2개다.
그리고 메모리 레지스터와 입출력 레지스터는 버퍼 레지스터와 주소 레지스터 이 두개로 구분된다.
그래서 정리해보자면, IR (Instrument Register), MBR (Memory Buffer Register), MAR (Memory Address Register), I/O BR (I/O Buffer Register), I/O AR (I/O Address Register) 이렇게 되어있다.
프로그램 카운터는, 명령어들을 순차적으로 실행시켜주는 역할을 한다.
IR은 현재 실행 중인 명령어를 저장한다.
Execution Unit은 그 명령어를 직접 실행한다.
MBR은 데이터나 명령을 임시로 저장하는 레지스터다
MAR은 메모리 주소를 임시로 저장하는 레지스터다
I/O AR은 입출력장치의 주소를 지정하는 레지스터다.
I/O BR은 입출력장치와 프로세서 사이에서 데이터를 교환하는 레지스터다.
주기억장치(RAM,메모리)는 명령어, 데이터를 담는 계층구조로 이루어져 있다.
입출력 모듈은 아까 설명하진 않았지만, 컴퓨터 시스템과 입출력 장치 사이의 중개자 역할을 한다.
프로세서의 명령을 해독하고, 데이터를 전송하고, 전송 속도를 조절하고, 현재 상태를 보고해준다.
내부에 버퍼가 있다. 버퍼는 데이터의 임시저장소다.
CPU 레지스터 구조에 대해서도 자세히 살펴보겠다.
프로그램 실행 관련 레지스터 23개
RAX : Accumulator
산술 혹은 논리 연산에 사용된다.
RBX : Base
메모리의 주소를 저장하는데 사용되는 첫번째 레지스터.
이것은 주로 배열이나 문자열을 위해 사용된다.
RBP와 혼동에서 주의 해야한다.
RCX : Counter
루프의 남은 횟수를 세는데에 사용된다.
0이 될 때 반복한다.
RDX : Data
큰 수를 저장할 때 쓰인다.
추가로 큰 수를 계산하는 데에도 쓰인다. RAX처럼.
RSI : Source Index
소스 데이터의 주소를 저장하는데에 쓰인다.
RDI : Destination Index
목적지 데이터의 주소를 저장하는데에 쓰인다.
RSP : Stack Pointer
스택의 최상단 값의 주소를 저장하는 레지스터다.
RBP : Base Pointer
스택의 접근할 값의 메모리 주소를 저장하는 레지스터다.
함수의 인자나, 지역변수를 위해 주로 쓰인다.
R8~R15 :
다목적 사용
EIP : Instruction Pointer
PC와 같은 역할을 한다. 다음 명령어를 저장한다.
메모리는 코드, 데이터, 힙, 스택 4개의 영역으로 나뉘는데 이에 따라 추가적인 레지스터가 생긴다.
CS : Code Segment
코드를 포함한 세그먼트(영역)의 주소를 담는 레지스터.
DS : Data Segment
데이터를 포함한 세그먼트(영역)의 주소를 담는 레지스터.
SS : Stack Segment
스택을 포함한 세그먼트(영역)의 주소를 담는 레지스터.
ES, FS, GS
데이터 혹은 세그먼트의 주소를 담는 다목적 레지스터.
시스템 관련 레지스터 12개에 대해서도 설명해 보겠다.
CR0~CR8 : 컨트롤 레지스터
CPU 제어 레지스
EFLAGS : 플래그 래지스터
플래그 레지스터는 현재 상태를 알려주는 역할을 하는 레지스터다.
GDTR : Global Descripter Table
GDTR은 링 레벨로 CPU의 메모리 접근을 제어하는 레지스터다.
링 레벨은 시스템 접근 가능 등급으로 숫자가 높을 수록 접근 가능한 양이 적어진다. 0이 제일 낮다.
IDTR : instruction Descripter Table
IDTR은 인터럽트가 발생했을 때, 어떻게 반응할지 결정하는 레지스터다.
LDTR : Local Descripter Table
우선 디스크립터란, 메모리 세그먼트 정보를 기술하는 자료구조이다.
LDTR은 프로그램별 메모리 세그먼트를 선정하는 레지스터다.
TR : Task Register
TR은 테스크 스위칭에 쓰이는 레지스터입니다.
MSR : Model Specific Register
MSR은 제조사가 정의한 기능이 담기는 레지스터 입니다.
실수 연산 및 SIMD 관련 레지스터에 대해서 설명 해보겠다.
FPU :
약자는 Floating Point Unit이고
부동소수점 계산 기능을 가진 레지스터다.
MMX :
약자는 Muti Meida eXtension :
멀티 미디어 기능을 향상시키는 레지스터다.
XMM
약자는 Extended Memory Manager
메모리 관리 기능을 하는 레지스터다.
이제 고성능 CPU 구조에 대해서도 살펴보겠다.
지금까지 여러 다양한 CPU가 나왔는데 트랜지스터의 개수는 기하급수적으로 꾸준히 많아져왔고
주파수와 전원 양은 크게 올라가다가 어느 순간부터 적게 커지기 시작했다.
코어의 개수도 크게 증가하다가 어느 순간부터 효율성 때문 일정하다.

고성능 CPU 구조를 알아보기 전에 이것이 나오게 된 배경을 먼저 살펴보겠다.
파이프라이닝 (pipelining)은 아래와 같이, 단계별로 여러 작업을 동시에 처리하는 기술이다.

한 번에 여러 명령어를 처리할 수 있어서 처리속도가 높아진다.
단, 4가지의 조건이 충족돼야 효율적이다.
균등성, 동일성, 독립성, 효율성이다.
먼저, 균등성이란 작업의 단계별 길이가 일정해야한다는 것이다.
그 다음에, 동일성이란 작업의 종류가 다 같아야 한다는 것이다.
독립성이란 작업별 종속성이 없고 개별적으로 처리해도 문제가 없다는 뜻이다.
효율성이란, 파이프라인의 깊이에 따른 비용을 최소화 해야한다는 것이다.
그다음에 CPU 내에 파이프라인을 한번에 여러개 두고 명령을 더 많이 동시에 수행하는 구조도 있다.
이를 슈퍼 스칼라라고 한다.
그 예로 Intel Nehalem은4-와이드구조를 보여주겠다.

파이프라인의 깊이에 따른 효율성은 아래 그림과 같다.

파이프라인 깊이로 시스템 성능을 늘리는 데에는 한계가 있다.
왜냐하면 명령어의 개수가 증가할 수록 파이프 라인의 4대 효율성 조건을 모두 충족하기가 어렵기 때문이다.
그리고 이 파이프라인을 잘 활용하기 위해 만들어진 구조가 다중코어 구조(multi-core)야.
여러개의 CPU를 하나의 CPU로 통합한 구조다.
SIMD와 MIMD가 있다.
SIMD는 Single Instrument Multiple-Data Stream,
MIMD는 Multiple Instrument Multiple-Data Stream이다.
SIMD는 하나의 명령어로 여러 데이터를 한번에 처리하는 구조이고
MIMD는 여러 명령어로 여러 데이터를 한번에 처리하는 구조이다.
구조는 아래와 같다.

CU : 제어유닛
PU : 프로세싱 유닛
MM : 메모리 모듈
IS : Instrument Stream
DS : Data Stream
근데 멀티 코어 말고 한 CPU로 파이프라이닝을 쓰는 방법도 있다.
한 CPU를 여러 CPU처럼 보이게 하는 기술이다. 이게 바로 동시 다중 스레딩.
Simultaneous Multi-Threading : SMT라고 부른다.
3. CPU 명령어
지금까지 CPU의 레지스터에 대해서 알아봤고
이제 CPU의 레지스터가 명령을 실행하기 위해서 필요한 명령어에 대해서 알아보겠다.
CPU는 명령어를 받으면 그것을 약속된 명령대로 작동시킨다.
기계어 또는 기계 명령어는 CPU가 인식할 수 있는 명령의 집합이다.
기계어는 2종으로 나뉜다.
1. 기계 명령어 형식 : 연산코드(opcode) 3비트와 피연산자 12비트로 나뉜다. 16비트다.
연산코드(opcode)의 예를 들자면 0001가 있다.
메모리에 저장된 값을 AC에 적재하라는 뜻이다.
2. 정수 형식 : 부호 1비트와 절대값 15비트로 이루어 진다.
Opcode 형식의 명령 종류에 대해서 살펴보겠다.
소개할 것은 총 12개다.
여기서 X, Y는 16진수고, R, S, T는 레지스터다.

종류가 총 12가지인데 외우는 방법은 112233이다.
이동 명령 1개
삽입 명령 1개
이동 명령 2개
산술 연산 명령 2개
논리 연산 명령 3개
특수 기능 명령 3개
라는 뜻이다.
여기서 더 자세하게 설명을 해보겠다. ( 레지스터 : R, S, T, 메모리 or 16 진수 : X, Y)
이동 명령 1개 : RXY : XY → R
삽입 명령 1개 : RXY : R ← XY
이동 명령 2개 : RXY : R → XY
0RS : R → S
산술 연산 명령 2개 : RST : S + T = R (2의 보수 형태로)
RST : S + T = R (부동소수점 형태로)
논리 연산 명령 3개 : RST : S ○ T = R (OR)
RST : S ○ T = R (AND)
RST : S ○ T = R (XOR)
특수 기능 명령 3개 : RST : S ○ T = R (우측 ROTATE)
RXY : R의 값과 0번 레지스터의 값이 같은지 확인하고 나서 같다면 XY 메모리 주소로 이동한다.
틀리다면 그대로 속행한다.
000 : 명령의 진행을 중단한다.
4. CPU 명령 실행 과정
아까전에 살펴본 CPU와 내부 요소들로 명령 실행 과정을 살펴보겠다.

1단계 : PC 카운터에서 순차적으로 명령어를 메모리에서 하나씩 받아아와서 IR에 저장한다.
이를 위해 PC → 주소 버스 → 메모리 → 데이터 버스 → IR을 거친다.
메모리에서 명령어를 받아 낼 때는 총 두 셀을 이용한다. 셀 하나당 16진수로 두글자고 명령어는 16진수로 4글자이기 때문이다. 비트로는 8비트, 바이트로는 1바이트 크기이기 때문이다.

2단계 : IR은 Execution Unit을 통해서 현재 담긴 명령어를 실행한다. mov 명령어는 메모리의 값을 레지스터로 이동시키는 명령어 이므로, 우선 메모리를 참조하기 위해 IR → 주소 버스 → 메모리 이렇게 간다.
그리고 받은 데이터를 레지스터로 옮기기 위해 메모리 → 데이터 버스 → 임시 레지스터 → 레지스터 이렇게 간다.
그리고 CPU 주기, 기계 주기라는 것도 있다.
CPU가 프로그램 카운터의 명령어를 명령어 레지스터에 저장하고 해석하고 실행하는 것을 반복하는 것을 말한다. 시동이 꺼질때까지 반복한다.
이것들을 자세하게 표현하면 아래와 같다.
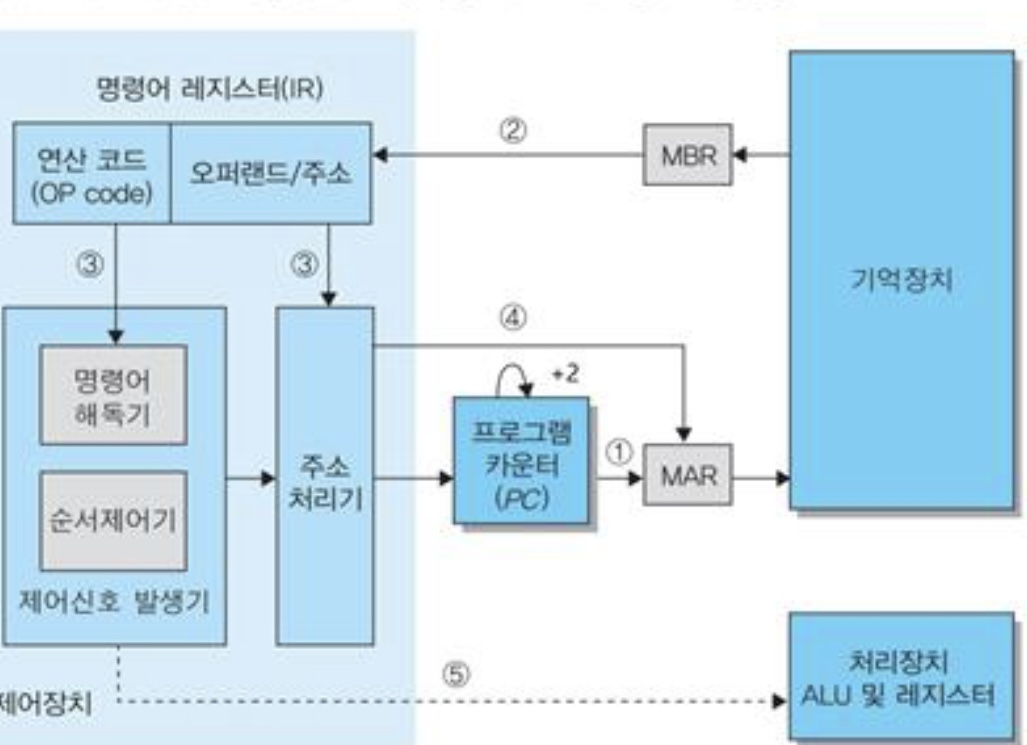
1. 맨 처음에는 프로그램 카운터가 명령어의 주소를 MAR에 넣는다.
2. 그걸로 기억장치의 명령어를 찾고 MBR를 거쳐서 IR에 넣는다.
3. 연산코드는 제어신호 발생기 안의 명령어 해독기에 넣고 해독하고, 피연산자는 주소처리기에 넣는다.
4. 그리고 해석된 명령어의 소스 데이터와 목적지 데이터가 주소처리기를 거쳐서 MAR에 들어가게 한다.
5. 처리장치 ALU에 연산을 요청한다.
5. 제어기
지금까지 데이터 조작 장치에서 CPU 위주로 살펴봤고 그다음 추가적으로 제어기라는 것에 대해서 살펴보겠다.

1-1.에서 설명하진 않았지만, 사실 버스와 장치 사이에 위치하여 데이터와 명령어의 송수신을 제어하는 장치가 있다.
이를 제어기라고 한다.
예를들어, CD-ROM, 마우스, USB, 디스플레이, 프린터, 스캐너, 스피커에 있다.
메인보드와 각종 카드에 부착되어 있기도 한다. 여기서 카드는 특정 기능을 수행하는 회로다. 메인보드와 연결되어 있다.
마이크로프로세서이기도 하다. 마이크로프로세서란 CPU(프로세서, 중앙 처리 장치)와 구분되고 CPU의 역할을 일부 분산해서 대신 처리해주는 소형 CPU다.
메인보드란 컴퓨터의 여러 장치(CPU, RAM, 각종 카드, 하드 드라이브)와 연결되어 전원을 공급해주고 신호를 중개해주는 장치를 말한다.
CPU에 의해 통제를 받는다. 자신의 상태를 인터럽트를 통해 CPU에게 전달한다.
< 2 > 데이터 조작 SW
지금까지 데이터 조작 장치에 대해서 살펴봤고 이번엔 SW 측면에서 주로 살펴보겠다.
1. 컴파일러와 링커
데이터를 조작하기 위해선 소스 코드 파일을 여러 단계로 바꿔야 한다.
첫째로 컴파일러가 소스 코드를 기계어로 바꾼 파일을 오브젝트 파일이라고 한다.
이 오브젝트 파일 여러개를 링커라는 SW를 이용해서 하나로 합친 것을 실행 파일(수행 파일)이라고 한다.
이 실행파일은 유닉스, 리눅스에서는 ELF라고 한다.
Executable and Linkable Format, 실행가능하고 연결할 수 있는 형식이라 뜻이다.
그리고 윈도우 에서는 PE라고 한다.
Portable Executable, 휴대가능하도 실행할 수 있다는 뜻이다.
2. 운영체제
그리고 CPU는 기계어를 읽을때, 0과 1만 볼 수 있어서 이게 데이터인지 명령어인지 알 수 없으므로
운영체제는 미리 메모리를 코드 영역, 데이터 영역, 힙 영역, 스택 영역으로 나누고 각기 정해진 곳에 데이터와 명령어를 넣음으로써 어떤 식으로 해석해야할 지 알 수 있도록 한다.
코드 영역에는 코드를, 데이터 영역에는 정적 변수나 전역 변수를, 힙 영역에는 사용자가 동적 할당을, 스택 영역에는 함수 인자나 지역변수를 넣는다.
< 3 > 데이터 조작 연산
데이터 조작 SW에 대해서 지금까지 살펴봤고 지금부턴 데이터 조작 연산에 대해서 살펴보겠다.
1. 마스킹
마스킹은 데이터에서 불필요한 부분을 지우는 연산이다.
피연산자 비트에서 지워질 부분에 해당하는 비트는 0으로, 나머지는 1로 한 마스크 비트를 만들고
마스크 비트와 피연산자 비트를 AND 연산하는 것이다.
이것을 쓰는 예로는 RGB 이미지에서 적색 요소만 지우기 위해서 적색 마스크와 이미지를 AND 연산하면 청색과 녹색만 남기는 것이다.

또 다른 예로는 1의 보수 비트 행을 만드는 것이다. ( 비트 반전을 하는 것이다. )
하는 방법은 그냥 1로만 된 비트 행과 피연산자가 될 비트 행을 XOR 연산 하는 것이다.

2. 쉬프트 (자리이동) 연산
Rotational Shift or Circular Shift (회전 or 순 쉬프트)
좌측 혹은 우측으로 설정한 횟수만큼 비트를 옮기는 것이다.
비트 영역에서 벗어난 값은 다른 방향에서 비트가 없어진 만큼 다시 채워주면 된다.
채워주는 값은 벗어난 값과 동일하다.

Logical Shift (논리적 쉬프트)
여기서는 채워지는 값이 항상 0이다.
Arithmetic Shift (산술적 쉬프트)
여기서는 왼쪽 쉬프트(곱하기 2) 할때만, 무조건 0으로 채워지고
오른쪽 쉬프트(나누기 2) 할때는, 부호 비트와 동일한 값으로 빈 비트가 채워진다.
산술적 쉬프트는 부동소수점의 덧셈에서도 활용할 수 있다.
예를 들어 0.1110 * 2^4 + 0.1100 * 2^2는 바로 계산하기가 어렵다.
하지만, 0.1100에 나누기 2를 두번하고 2^2에 곱하기 2를 두번 하면 계산하기가 쉬워진다.
그 결과 0.1110 * 2^4 + 0.0011 * 2^4가 된다.
합하면 1.0001 * 2^4가 된다.
그 다음에 마지막으로 정규화도 해야한다. 0.10001 * 2^5
< 4 > 데이터 조작을 위한 통신
지금까지 데이터 조작에 관한 연산을 살펴봤고 이번엔 데이터 조작을 위한 여러 통신 방식을 살펴볼 것이다.
1. 사상 I/O
사상 I/O로는 두가지가 있다.
메모리 사상 I/O과 포트 사상 I/O다.
먼저, 메모리 사상 I/O는 I/O 장치의 메모리를 RAM에 할당을 하고 CPU가 RAM에 접근하는 방식으로 I/O 장치에 접근하는 것이다. (LOAD, STORE등)
더 빠르고 로직이 단순해진다. RISC 방식에서 쓴다.
그리고 결국 CPU가 RAM의 I/O 메모리 영역에 명령을 내리면, 제어기는 그 데이터를 받고 명령을 수행한다.
포트 사상 I/O는 CPU가 I/O와의 통신을 위해 별도의 메모리 공간(버퍼), 통로(I/O 버스), 명령어(IN, OUT)을 만들어 두는것이다. 어셈블리어 프로그램에서 입출력 명령어를 확인하기가 용이함.
CISC에서 주로 사용함.
주기억공간이 부족할때 용이함.
포트 사상 I/O를 쓰면 CPU가 CPU보다 훨씬 느린 I/O와의 통신을 위해 대기를 하면서 속도가 느려지는 것을 방지하기 위해 직접 메모리 접근 (Direct Memory Access; DMA)를 써야한다.
DMA는 I/O 제어장치가 CPU를 거치지 않고 바로 시스템 버스를 통해 메모리에 접근 할 수 있도록 하는 장치다.
DMA는 I/O 버스와 시스템 버스 사이에 있다.
CPU의 데이터 전송 제어 기능을 분담해준다. I/O 제어 장치가 CPU에 비해 많이 느려서 I/O 제어 장치의 일 처리를 기다리느라 CPU 전체 성능이 떨어지는 것을 방지한다. 그래서, I/O 장치와 CPU가 동시에 작동 될 수 있게 해서 성능을 증가 시킨다. 버스는 한번에 한 일만 사용할 수 있기때문에 DMA와 CPU가 버스 사용권한을 두고 경쟁해서 폰 노이만(CPU와 메모리가 하나의 버스만 이용하는 구조) 병목 현상이 나타날 수 있다.
2. 핸드셰이킹 (HandShaking)
핸드셰이킹은 데이터 송신 시, 송신 측과 수신 측 양쪽 모두 제어 신호를 발생시켜서 양측의 존재를 확립시키는 과정을 의미한다.
핸드셰이킹은 두가지로 나뉜다.
송신측 개시 핸드셰이킹, 수신측 개시 핸드셰이킹이 있다.
두가지의 간단한 차이점은 어느측이 먼저 신호를 보내는지, 그리고 수신측이 수신 신호를 발생시키는지 준비 신호를 발생시키는 지이다.
먼저 송신측 개시 핸드셰이킹은 송신측이 데이터를 데이터 버스에 올려놓고 데이터 활성 신호를 발생시킨다.
그러면 수신측이 데이터 버스의 데이터를 받고 데이터 수신 신호를 발생 시킨다.
그러면 송신측이 데이터 버스에 보내는 데이터 신호를 끊고, 데이더 활성 신호도 끊는다.
그럼 마지막으로 수신 측도 데이터 수신 신호의 발생을 끊고 다음 데이터 수신을 준비한다.
그 다음 수신측 개시 핸드셰이킹은 제일 먼저, 수신측이 데이터 수신을 준비하고 데이터 준비 신호를 보낸다.
그 다음 송신측이 데이터 버스에 데이터 신호를 보내고 데이터 활성 신호를 보낸다.
그 다음 수신측이 데이터를 수신하고 데이터 준비 신호를 끊는다.
그 다음 송신측이 데이터 버스에 데이터 송신을 끊고 데이터 활성신호도 끊는다.
3. 직렬 & 병렬 전송
데이터 전송을 위해선 이 두가지 방법을 주로 사용한다.

먼저, 직렬 전송은 전송 거리가 멀때 주로 사용을 하는 방법이다.
클럭 속도(CPU의 초당 작업 횟수)를 높여서 전송속도를 높일 수도 있다.
대표적으로 USB에서 사용을한다.
그 다음 병렬 전송이 있는데, 전송 거리가 짧을때 주로 사용하는 방법이다. 주로 CPU와 그것의 주변 장치들 사이에서 사용한다. 모든 비들을 동시에 도착시키기 위해서 송수신측의 동기화를 위한 대기시간이 필요하다.
부가적으로 통신속도 단위를 설명하겠다.
기본적으론 bps ( bit per seconds )가 있는데 초당 비트 수 라는 뜻이다. 여기에 여러 단어를 붙일 수 있다.
kbps (kilo - bps), mbps (mega - bps), gbps (giga - bps)
음악 재생에는 64kbps가 필요하다.
USB는 2.0 기준 60MB/S
3.0 기준 625MB/S
Thunderbolt는5GB/S 이다.
대역폭(bandwidth)라는 것도 있다.
통신 경로의 최대 전송 속도 또는 용량을 말한다.

Broadband 서비스는 넓은 대역폭을 사용한다(=주파수가 넓다)는 의미이다.
(전파의 진동횟수(주파수)가 높다랑 다른 의미, 주파수의 넓이란 최고 주파수 - 최저 주파수이다. 그러니까 넓은 대역폭이란
최고 주파수가 높다는 것을 간접적으로 의미하기도 한다.)
그리고 병렬 전송의 일종으로 다중화 (multiplexing)에 대해서 설명하겠다.
다중화는 하나의 물리적인 통신 장치를 여러개의 논리적인 통신 채널( 논리적인 통신 경로)로 사용할 수 있게 하는 작업이다.
다중화는 두가지로 나뉜다. 주파수 분할 ( FDM , Frequency Division Multiplexing )과, 시분할 다중화 (TDM, Time Division Multiplexing)이다.
FDM은 한 주파수의 영역을 여러 채널을 위해 여러 범위로 나누고, 한 채널씩 한 범위를 할당하는 다중화 방식이다.
TDM은 여러 채널을 위해 시간 슬롯을 여러개 만들고, 한 채널 당 한 시간슬롯 씩 주고 각자 배정된 시간만큼 채널들이
돌아가면서 쓰게하는 다중화 방식이다.
'BackEnd > Computer Architecture' 카테고리의 다른 글
| 컴퓨터 시스템 개론 : 4장 : 네트워크와 인터넷 (6) | 2024.04.27 |
|---|---|
| 컴퓨터 시스템 개론 : 3장 : 운영체제 (5) | 2024.04.26 |
| 컴퓨터 시스템 개론 : 1장 : 데이터의 저장 (2) | 2024.04.17 |
| 레지스터 구조 (2) | 2024.04.13 |
| OPCODE + ADDRESS : 16진수 4자리를 이용한 기계어 표현법 (0) | 2024.03.28 |




댓글