2024년 1학기때 컴퓨터 시스템 개론에서 배운 것을 설명할 것이다.
1. 개요
컴퓨터 시스템의 작동원리와 기초적인 지식에 대해서 배워볼 것이다..
먼저 컴퓨터는 데이터를 저장부터 해야 데이터를 처리하면서
인간에게 유용함을 제공해줄 수 있겠으니 컴퓨터의 데이터의 저장방법에
대해서 먼저 알아볼것이다..
저장된 데이터를 어떻게 읽어야 하는지 알기 위해 데이터의 표현법도 알아볼것이다..
그리고 더 효율적으로 저장하기 위해 데이터를 압축하는 방법도 배울것이다..
저장을 해놨어도 전달하는 과정에서 여러 이유로 일부가 유실 될 수도 있어서
유실 여부를 검사하는 방법도 배울것이다.
목차
1장 : 데이터의 저장
< 1 > 데이터 저장 장치의 기초
1. 비트 : 저장 개념 최소단위
2. 플립플롭 : 저장 장치 최소단위
3. 게이트 : 플립플롭 구성요소
4. 플립플롭의 게이트 구성방식
5. 게이트의 활용 : 전가산기, SW 요구명세서
< 2 > 데이터 저장 장치의 심화
1. 주기억장치
2. 하드디스크의 구조
3. 하드디스크의 저장 방식
4. 디스크 포맷팅
< 3 > 데이터 표현 규칙
1. 위치적 기수법
2. 이진법, 16진법, 고정소수점 표기법
3. r의 보수 표기법
4. x-초과 표기법
5. 부동소수점 표기법
< 4 > 데이터 압축법
1. RLE
2. FDE
3. 차등인코딩 & 사전 인코딩
4. GIF & PNG
5. MPEG & MP3
6. JPEG
< 5 > 데이터 오류 탐지법
1. 패리트 비트
2. 검사합 오류 탐지법
1-1. 비트 : 저장 개념 최소단위
컴퓨터는 비트라는 개념으로 정보를 저장한다.
비트는 0 또는 1을 갖는 하나의 단위이고
보통 0을 거짓 1을 진실로 해석할 수도 있다.
이 경우, 부울이라고도 한ㄷ.
정리하자면 부울은 참 또는 거짓을 갖는 하나의 단위이다.
1-2. 플립플롭 : 저장 장치 최소단위
비트라는 개념으로 '플립플롭'이라는 장치를 만들어서 데이터를 저장한다.
플립플롭은 상태변경 신호가 입력될때까지 현재 상태를 유지하는 장치를
말한다.
플립플롭을 많이 만들면 데이터를 많이 저장할 수 있다.
플립플롭 여러개로 만든 제일 작은 장치가 레지스터다.
플립플롭 16개를 쓴 레지스터는 저장용량이 16비트다.
그다음으로 큰 장치가 SRAM(Static Random access memory)야.
SRAM의 RAM은 참조할 위치를 무작위로 선정해도 언제든지 접근 가능한
메모리 라는 뜻이고 S가 붙은 이유는 SRAM의 플립플롭은 한번 정보를 넣고나면
계속 가만히 현재 상태를 유지하기 때문이다.
반면 DRAM은 축전기라 가만히 현재 상태를 안유지하고 계속 방전되면서
메모리가 변화하기 때문이다.
1-3. 게이트 : 플립플롭 구성요소
플립플롭의 원리에 대해서 설명 해보겠다.
먼저 플립플롭은 여러 '게이트'로 이루어진다.
게이트의 종류는 6가지야

AND, OR , NOT, NAND, NOR, XOR이 있다.
먼저 AND는 이렇게 두 개의 입력값을 받아서 두 개가 모두 1(참)이면 1(참)을 반환한다.
개복치처럼 생겼다.
OR은 이렇게 두 개의 입력값을 받아서 둘 중 하나가 참이면 참을 반환한다.
부메랑처럼 생겼다.
NOT은 하나의 입력값을 받아서 그것의 반대 값을 반환한다.
삼각형과 원을 붙인 형태다.
NAND는 두 개의 입력값을 받고 반환값은 AND의 반환 값을 NOT 게이트에 보내서 나온 값을 가진다.
NOT 게이트의 삼각형만 AND 게이트 꼴(개복치)로 바꾼 형태다.
NOR은 두 개의 입력값을 받고 OR의 반환값을 NOT 게이트를 지나게 한 값을 반환한다.
NOT 게이트의 삼각형만 OR 게이트 꼴(부메랑)로 바꾼 형태다.
XOR은 두 개의 입력값을 받고 두 값이 서로 다를때만 참을 반환한다.
형태는 OR 게이트(부메랑)에 곡선을 그은 형태다.
1-4. 플립플롭의 게이트 구성방식
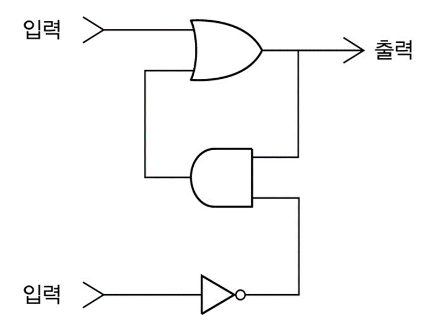
이렇게 생겼다.
설명을 해보자면 일단 두개의 입력을 받고 하나를 반환하는 형태인데
한 입력에서는 OR이 있고
다른 입력에서는 NOT이 있다.
그리고 그 두 게이트 사이에 AND가 있다.
AND는 나머지 두 게이트 방향과 반대방향이다.
그리고 AND의 반환 값은 OR의 입력값 중 하나로 들어간다.
그리고 최종적으로 OR이 최종 반환값을 내보냄과 동시에
같은 값을 AND의 입력 중 하나로 넣는다.
직접한번 꼭 그려보자.
그리고 이제 플립플롭에 값을 저장하는 방법을 알아볼 건데
매우 단순하다.
그냥 위쪽에 1을 넣으면 된다.
값을 빼려면 밑에 1을 넣으면된다.
머릿속으로 그 과정이 잘 되는지 확인 해보고 안되면 아래 사진을 확인한다.

1-5. 게이트의 활용 : 전가산기
플립플롭으로 비트값을 저장하는 방법을 배웠는데
게이트의 추가적인 활용법을 배워보겠다.
전가산기와 SW 요구명세서를 만들 수 있다.
먼저, 전가산기란 세 비트를 입력받고 그것들의 합계와 올림비트를 반환하는 장치다.
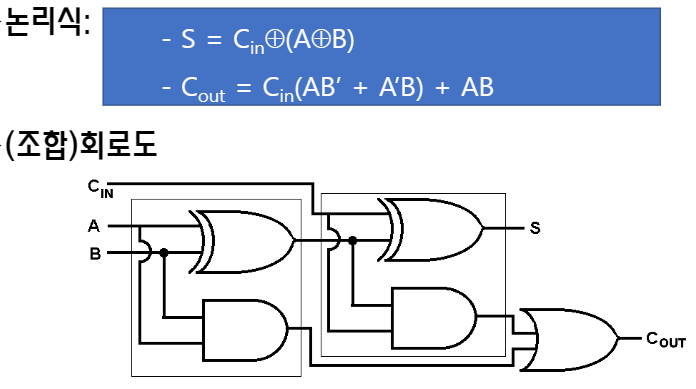
먼저, S가 합을 의미하는데 세비트로 XOR 연산을 두번하면 구할 수 있다.
그림도 그냥 간단하게 그리면 돼.
C는 올림비트를 의미하는데, A와 B를 XOR 연산한것과 C를 가져온다.
두개를 AND 연산한다.
A와 B를 AND 연산한다.
두 AND 연산 결과를 OR 연산하면 C를 구할 수 있다.
게이트가 매우 단순하고 명확하다 보니까 SW 요구 명세서 작성 때도 잘 쓰인다.
명확하게 SW가 해야할 일을 써야 아무래도 일 할때 오해가 안생겨서 좋다.
활용한 예를 들자면 아래와 같다.
<엘레베이터 명세서> (IMPLIES는 추가하다 연산)
▪(FLOOR=1 OR FLOOR=2) AND(NOTMOVING) AND BUTTON_PUSHED IMPLIES FRONT_DOOR_OPENS
▪(FLOOR=3 OR FLOOR=4) AND(NOTMOVING) AND BUTTON_PUSHED IMPLIES REAR_DOOR_OPENS
▪그외의 경우에 시스템은 아무것도 하지 않는다.
2. 데이터 저장 장치의 심화
지금까지 플립플롭과 그에 관한 것들을 설명했고 이제 심화적이고 더 큰 장치인 주 기억장치에 대해서
설명하겠다.
2-1. 주기억장치
주기억장치는 데이터 저장을 위한 비트 저장소다.
여기에는 코드와 데이터가 저장된다.
주기억장치는 4개의 영역으로 나뉘어진다..
코드, 데이터, 힙, 스택
왜냐하면, 이진수 ex) 0101010 으로만 저장되기 때문에 미리 구분을 안해둔 상태에서 저장을 해버리면
저장된 것을 코드로 해석해야 하는지 데이터로 해석해야 하는지 알기 어렵기 때문이다.
코드 영역에는 코드가, 나머지 영역에는 데이터가 저장된다.
주기억장치는 아래 컴퓨터 하드웨어 구성에서 RAM에 해당한다.

그리고 주기억장치는 아래 메모리 계층구조에서 3번째 서열에 해당한다.

서열이 높을 수록 속도가 빠르고 비트당 기억장치의 비용이 증가하고 메모리 크기가 감소한다.
그리고 꼴지 서열인 보조기억 장치를 제외한 모든 영역의 프로그램과 데이터는 바로 직접 읽을 수 있다.
보조기억 장치의 내용은 주기억 장치로 옮겨야 실행 가능하다.
2-2. 하드디스크
이제 아래 컴퓨터 하드웨어 구성에서 하드디스크에 대해서 배워보겠다.
배우는 순서는 구성요소, 제어장치, 기록방식이다.
하드디스크도 RAM과 기억장치라는 점에서 정의하면 동일하다.
하지만 구성은 다르다.
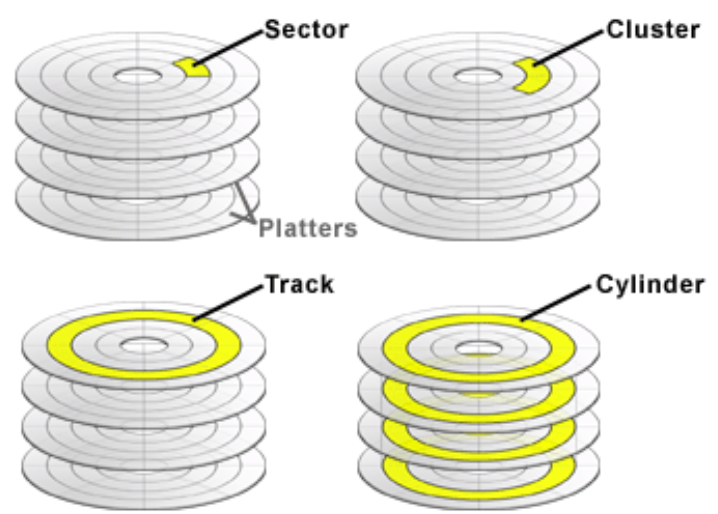
플래터,스핀들,암,헤드,구동기 5개가 주 구성요소다.

직접 한번 그려보자.
각 구성요소 기능은 아래와 같다.
구동기 : 암을 움직이는 장치
암 : 구동기와 헤드를 연결하여 헤드를 움직이는 장치
헤드 : 플래터에 데이터를 읽고 쓰는 장치
플래터 : 데이터를 저장하는 원판
트랙 : 플래터의 동심원
섹터 : 트랙에서 일정 크기로 나뉘어지고 데이터가 한번에 읽고 쓰여지는 최소 단위
실린더 : 플래터에서 같은 위치에 있는 동심원, 프로세서가 데이터를 읽고 쓸때 실린더 번호를 조회하여 빠르게 접근함
디스크 제어 모듈은 아래처럼 생겼다.

프로세서, 디스크 캐시, 구동기, 입출력 버스 인터페이스 4개로 구성되며 디스크와 호스트 컴퓨터 사이에서 작동한다.
프로세서는 입출력 버스 인터페이스로부터 입출력 명령을 받아서 구동기에게 전달한다.
디스크 상태정보를 인터페이스에게 전달하기도 한다.
디스크 캐시는 입출력할 정보를 임시저장한다.
구동기는 디스크의 하드웨어를 작동시켜서 탐색 / 읽기 / 쓰기를 하게 한다.
마지막으로 호스트 컴퓨터와 디스크 제어 모듈이 통신하는 방법은
입출력 버스를 이용하는 것이다.
2-3. 하드디스크의 저장방식에 대해서 설명하겠다
3가지가 있다.
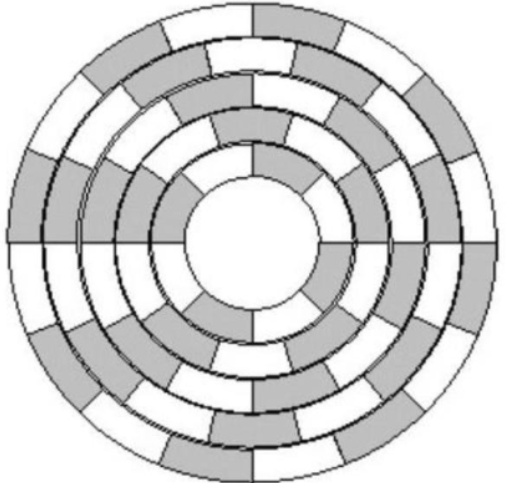
등각속도(CAV, Constant Angular Velocity), 등선속도(CLV, Constant Linear Velocity), 다중구역기록(MZR, Multiple Zone Recording)
등각속도 방식(CAV, Constant Angular Velocity)은 플래터가 일정한 속도로 회전하면서 트랙에 일정하게 조금씩 데이터를 쓰거나 읽는 방식이다.
바깥쪽 트랙은 안쪽보다 더 큰데 안쪽과 동일한 크기로 읽거나 쓰기 때문에 낭비가 발생한다.
등선속도 방식(CLV, Constant Linear, Velocity)은 등각속도를 조금 개선한 방식으로써, 구동장치의 속도를 조절하면서 트랙의 크기에 비례하여 읽고 쓸 수 있도록 하는 것이다.
다중구역기록 방식(MZR, Multiple Zone Recording)은 플래터 상의 비슷한 위치에 있는 트랙들을 묶고 몇개의 영역으로 나누어서 거기에 저장하는 방식이다. (인접한 섹터끼
등선 속도 방식처럼 효율적으로 저장 가능하다.
트랙 당 섹터 수는 모든 실린더에서 동일하다.
바깥 쪽으로 갈 수록 섹터 수는 많아진다.
2-4. 또한, 디스크를 사용하기 전에 포맷팅이라는 것을 해둬야한다.
디스크 포맷 방식은 저수준 포맷팅, 고수준 포맷팅으로 나누어 진다.
저수준 포맷팅을 할 땐, 아래처럼 섹터 데이터의 앞 뒤에 여러 요소들을 기록한다.

각 요소들의 기능은 아래와 같다.
gap는 섹터 사이의 빈 공간
sync는 데이터의 정확한 위치를 식별하기 위한 신호이다.
address mark는 데이터의 주소로써 데이터를 읽거나 쓸 때 해당 주소로 데이터의 위치를 찾게 된다.
ECC란 Error Correction Code로써 저장된 데이터가 유실됐을때 이것으로 데이터를 복구한다.
그리고 섹터에서 데이터의 크기는 달라질 수 있지만, 포맷팅때 쓰이는 보조적인 위 요소들은 크기가 항상 일정하다.
그래서 섹터의 크기가 커질 수록, 데이터의 크기가 커질 수록 데이터 저장 효율은 증가한다.
에러 커렉션 코드만 50이고 나머진 다 합쳐서 15다.
물론 데이터가 512 바이트 크기일때만 적용되고 4096 바이트일땐, ECC만 두 배가 된다.
그리고 512 바이트 섹터 같이 섹터 하나의 크기를 구하기 위해선 데이터 크기와 포맷팅 요소들의 크기를 더하면 된다
그래서 512 바이트 섹터는 512 + 50 + 15 = 562 + 15 = 577 바이트가 된다.
고수준 포맷팅은 부팅하기 전에 디스크의 구조를 만들고 필요한 것을 기록하는 작업이야.
대표적으로 세가지, 파일 시스템, 파티션 테이블, 부팅 코드로 나뉘어.
파일 시스템은 만들어 두면 운영체제가 주로 사용해.
운영체제는 컴퓨터 시스템의 자원들을 효율적으로 다루고 사용자에게 편의를 제공하는 프로그램이야.
컴퓨터를 사용하기 전에 먼저 설치 해야하는 기본 소프트웨어야.
파티션 테이블은 디스크를 다룰 때, 사용해.
부팅 코드는 부팅할 때, 사용을 해.
부팅 방식은 MBR 방식과 GPT 방식으로 나뉘어.
MBR은 기본(주) 파티션과 확장 파티션으로 나뉘어.
주 파티션에는 운영체제를 설치하고 확장 파티션에는 운영체제 외의 나머지의 것을 설치해.
MBR은 최대 4개의 파티션을 만들 수 있어.
MBR은 최대 2TB까지만 쓸 수 있고 그 이상인 경우엔, GPT 방식을 사용해.
GPT 방식은 UEFI 펌웨어를 가진 현대 컴퓨터에서만 사용을 해.
Unified Extensible Firmware Interface가 약자야.
아래와 같이 이루어져 있어.

앞쪽에는 보호 MBR 그리고 기본 GPT 헤더, 기본 파티션 테이블이 있어.
그 다음으로 부트섹터와 피티션이 한 쌍씩 있어.
그 다음 빈 공간이 나오고.
마지막으로 백업 파티션 테이블과 백업 GPT 헤더가 나와.
보호 MBR은 MBR 포맷팅과 호환되게 하고 MBR이 아닌 GPT 방식으로 디스크를 읽고 쓰게하는 하는 기능이야.
기본 GPT 헤더는 이 디스크의 파티션의 구조 정보를 담고 있어.
기본 파티션 테이블은 파티션들에 관한 세부 정보를 담고 있는 테이블이야.
파티션 테이블은 디스크를 여러 개의 파티션으로 분할한 뒤 저장하는 저장방식을 의미해.
최대 128개까지 만들 수 있어.
부트 섹터는 파티션의 첫 섹터야. 부팅 프로그램을 담을 수 있어.
파티션은 데이터를 저장하는 공간이야.
사용자 데이터, 운영체제, 프로그램을 저장할 수 있어.
비어있는 디스크 공간은 파티션을 새로 만들고 쓸 수 있어.
마지막으로 백업 GPT 헤더와 백업 파티션 테이블이 있어.
각각 기본 GPT 헤더, 기본 파티션 테이블을 복사 해뒀다가
기존의 것이 손상되면 복구하는 용도야.
그리고 보호 MBR에 담긴 정보를 알아볼게.
보호 MBR 512 바이트에는 부트로더, 파티션 테이블 64바이트, 매직번호 2바이트가 담겨.
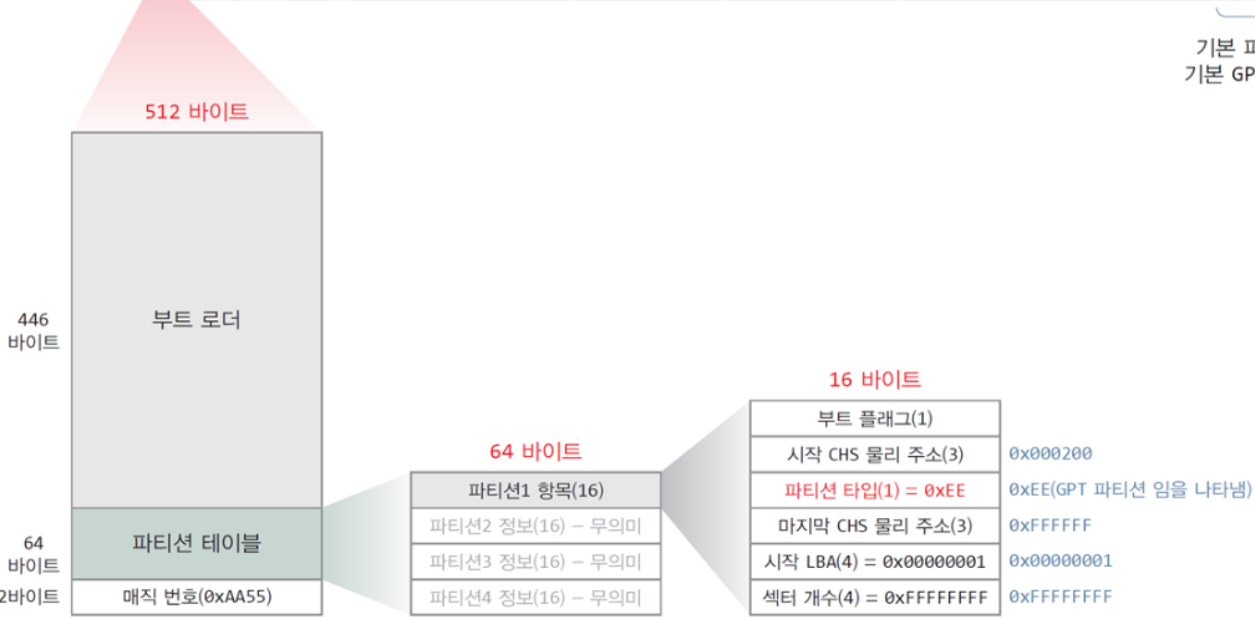
부트로더에는 운영체제가 메모리로 로드될 수 있도록 하는 프로그램이 담겨.
파티션 테이블에는 부팅 가능한 파티션들에 관한 여러 정보가 담겨.
매직 번호는 GPT 포맷임을 인식하게 하고, GPT 파티션 테이블의 시작 위치와 무결성 여부 정보를 담아.
3. 데이터 표현 규칙
지금까지 데이터 저장에 관한 장치를 배웠고 이제 데이터 저장에 관한 규칙을 배워 볼거야.
3-1. 위치적 기수법
우리는 이것을 위치적 기수법이라고 불러.
위치로 숫자를 나타내는 기수법이야.
기수법은 수를 시각적으로 나타내는 법을 의미해.
기수, 위치계수, 위치값로 구성되어있지.
기수는 위치적 기수법에서 쓸 진법을 결정하는 값이야. 2, 10, 16 같은 값으로 쓰여.
위치 값은 기수에 대한 가중치이자 수의 위치를 결정하는 값이야. 1, 2, 3 ... 같이 높은 자리의 수일수록 커져.
각각 1번째 수, 2번째 수, 3번째 수... 라는 뜻이야.
위치 계수는 수의 의미를 결정하는 값이야. 1 혹은 0이야.
예를 들자면 아래와 같아.
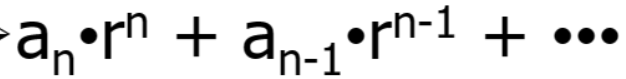
여기서 r이 기수이고 a가 위치 계수이고 n이 위치값이야
실제로 나타내게 되면 아래와 같아.

1011을 2, 10, 16진수로 나타낼 수 있어.
4자리 수니까 위치값은 3~0로 나타나고 위치 계수는 여전히 그대로 1,0,1,1이고
기수는 각 진법에 따라 변화하고 있어.
3-2. 이진법, 16진법, 고정소수점 표기법
위치적 기수법 외에도 이진법이라는 것이 있어.
2의 거듭제곱의 횟수라는 각 의미를 가진 비트들로 표현을 하는 방식이야.
자리수가 커질 수록 그에 따라 거듭제곱의 횟수도 증가해.
자리 수에 따른 거듭제곱의 횟수는 자리수 - 1 = 거듭제곱 횟수야.
1이면 해당 자리의 거듭제곱을 사용하는 거고 0이면 안쓴다는 의미야.
예를 들어 1010이면 첫번째 1은 4번째 자리야.
자리 수-1로 2의 3제곱이 되므로 8이 돼.
세번째 1은 2번째 자리야.
자리수-1로 2의 1제곱이 되므로 2가 돼.
따라서 1010은 8+2로 10을 의미해.
역으로 10을 이진수화 하는 방법은 2로 계속 나누면서 나머지 1이 발생 하는지 보는거야.
예를들어 10을 2로 나누면 몫은 5고 나머지는 0 따라서 첫째 자리는 0.
5에 2를 나누면 몫은 2 나머지는 1 따라서 둘째 자리는 1.
2에 2를 나누면 몫은 1 나머지는 0 따라서 셋째 자리는 0.
1에 2를 나누면 몫은 0 나머지는 1 따라서 넷째 자리는 1이 돼.
그 결과. 10은 1010이 되지.
소수를 표현할 수 있어.
먼저 고정소수점 자리 방식이야.
정수부.소수부로 나뉘어.
소수부의 비트는 뒤로 갈수록 1/2에 제곱을 한 값을 가져.
따라서 0.5를 표현하기 위해선 0.1이여야 겠지.
0.25를 표현하기 위해선 0.01이여야 하고.
덧셈 규칙은 이진수끼리 더할때 서로 같은 자리의 비트가 1이라면
자리 수를 하나 올리는거야.
예를 들자면, 01+01이면 10가 돼.
이진수 말고 16진법도 있어
그냥 이진수를 16진수로 축약적으로 표현을 한거야
고정소수점의 점부터 4비트씩 16진수로 표현을 하면 돼.
예를 들어, 0000.0001이면 0과 1을 의미하고 16진수는 0~9, A~F의 값을 지니므로 그대로 각 0.1로 표현한다.
1111.1110은 15와 14를 의미하고 16진수에서 그것은 F와 E를 의미하므로 F.E라고 적으면 된다.
3-3. r의 보수 표기법도 있어.
음수를 쉽게 표현하거나 뺄셈 연산을 하는 용도야.
먼저 1의 보수 표기법은
10000 - x의 결과로 표기하는 방법이야.
참고로 비트를 반전하는 것과 동일해.
1의 보수 방식으로 빼는 것은 피감수와 감수에서 피감수를 1의 보수로 바꾼 뒤에 더하는 것이야.
예를 들어 5 - 3 이면
0101 - 0011인데 1010 + 0011이 된다. 그럼 계산 결과는 1101인데, 올림비트가 발생하지 않는다면
마지막으로 한번 더 비트반전 하고 있으면 최하위 비트에 1을 더한다.
발생하지 않았으므로 결과는 0010, 2가 된다.
2의 보수 표기법은
11111 - x의 결과로 표기하는 방법이야.
1의 보수 표기법으로 표기한 후 1을 더하는 것과 동일해.
2의 보수 방식으로 빼는 방법은.
피감수와 감수에서 감수를 2의 보수로 바꾼 뒤에 더하는 것이야.
예를 들어 5-3이면
0101 - 0011인데 0101 + 1101이 된다.
더한 결과 10010이 된다. 올림비트가 발생하면 무시하고
안발생하면 2의 보수로 바꾼 뒤, 음의 부호로 바꾼다.
그 결과 2가 된다.
3-4. x-초과 표기법
추가로 x-초과 표기법도 있는데.
초과값을 정하고 그 초과값은 0이고 그 이상의 양으로 그 이하의 값은 음의 수로 정하는거야.
예를들어 8 초과 표기법을 설명 해보겠다.
8은 우선 1000이므로 1000은 0이다.
1001은 1이다.
0111은 -1이다,
그리고 이 비트들은 표현가능한 최대 범위를 가지고 있는데 이것을 넘는 값을 저장하게 되면 오류가 발생한다.
부호가 바뀐다든지 하는. 그것을 오버플로우라고 칭한다.
3-5. 부동소수점 표기법
이전에 소수를 설명하기 위해 고정소수점 표기법을 설명하였는데 이것을 쓰기 위해서는 무조건 최대 비트를 정해야 하는 단점이 있다. 이러면 필연적으로 오버플로우가 발생한다.
하지만 부동소수점은 정하지 않기 때문에 오버 플로우가 발생하지 않는다.
부동소수점은 부호 비트, 지수 비트, 유효숫자 비트를 가진다.
부호 비트는 부호를 결정하고 지수 비트는 2를 곱하는 횟수, 유효 숫자는 표현할 숫자를 표현한다.
우선 3을 표현해 보겠다.
유효숫자는 11, 부호는 0이 된다.
그리고 표현 과정에서 무조건 유효숫자는 소수점 뒤로 가게 된다.
이것을 원상 복구시켜주기 위해 지수 비트가 필요하다.
0.11를 11.0으로 바꿔주기 위해 2를 두번 곱해야 한다 따라서 지수 비트는 10이 된다.
그래서 최종적으로 1 10 11이 된다.
물론 지수 비트와 유효 비트에 비트를 얼마나 할당하는지에 따라 사이에 0이 몇개나 들어갈지가 결정된다.
각기 4비트 였다면
1 0010 0011이 된다.
덧붙여서, 32비트 부동소수점은 부호 1비트, 지수 8비트, 가수 23(=32-9)비트로 이뤄진다.
64비트 부동소수점은 부호 1비트, 지수 11비트, 가수 52(=64-12)비트로 이뤄진다.
4. 데이터 압축
데이터를 표현하는 방법을 지금까지 살펴봤고, 메모리를 덜 쓰면서 데이터를 표현하는 방법을 이제 알아볼 것이다.
그것을 데이터 압축이라고 하는데 정의는 데이터의 본래 정보를 유지하면서 데이터 크기를 줄이는 것을 의미한다.
데이터 압축법은 손실 압축법과 무손실 압축법으로 나뉘는데 무손실은 손실이 안나는 반면 손실 압축법은 손실이 날 수도 있다.
4-1. RLE
가장 먼저 Run Length Encoding가 있다. 이것은 반복되는 문자와 그것의 반복되는 횟수를 기록함으로써 압축하는 것이다.
예를들어 AAAEEEBBBB라면 A3E3B4라고 적는 것이다.
또 1 사이에 들어간 0의 개수만 기록할 수도 있다.
예를들어 10000110010001이면
0이 4개, 0개, 2개, 3개이므로 0100 0000 0010 0011이 된다.
4-2. FDE
그다음으로 Frequency Dependent Encoding이다.
RLE가 길이에 초점을 맞췄다면, FDE는 반복 횟수에 초점을 맞춘다.
표현할 데이터에서 문자들의 반복 횟수를 정렬한 뒤에 문자별로 부여할 코드를 최적화 하는 것이다.
반복이 자주 될 수록 짧은 코드를, 안반복될 수록 긴 코드를 배정한다.

EDAEC순인데
00, 10, 11, 010, 111을 순서대로 부여하면 된다.
이런 식으로 만든 코드를 허프만 코드라고 칭한다.
4-3. 차등 & 사전 인코딩
우선 차등 인코딩 방법은 동영상 같은 여러 프레임들 사이에서 데이터 스트림의 변화가 급격하지 않고
이전 데이터 스트림이 약간씩만 변화했다면 그 차이만 기록하는 방식이다,.
사전 인코딩 방식은 입력된 여러 문장들중에서 자주 사용되는 단어들을 골라서 사전 형태로 만들어 두고
넣어둔 단어가 필요할때마다 해당 사전에서 참조만 하도록 하는 것이다.
4-4. 이미지 압축 : GIF & PNG
GIF는 Graphic Interchange Format (그래픽 내부교환 포맷)
의 약자다.
사전 인코딩의 예 중 하나이다.
256가지의 색상 팔레트를 미리 만들어 두고 이미지의 각 픽셀이 색상 팔레트에서 가장 가까운 값이 되도록 한다.
그것은 LZW 알고리즘이다.
PNG는 Portable Network Graphics (휴대용 네트워크 그래픽)
PNG는 무손실 압축 알고리즘인 deflate 알고리즘을 사용해서 압축한다.
그것으로 32비트 트루컬러를 표현한다.
트루 컬러는 실제로 볼 수 있는 모든 색상을 의미한다.
32비트에서 24비트는 색상을, 8비트는 투명도를 표현한다.
웹 상에서 투명을 지원한다.
차후 고화질 편집이 가능하다.
4-5. 이미지 압축 : JPEG
Joint Photographic Expert Graphic
차등 인코딩 방식을 사용한다.
8x8 픽셀 블록들을 만들고, 그 안에서 2x2 픽셀 영역안의 색차이들의 평균을 구하는 방식으로 압축하는 방식이다.
BMP (Bit Map, 무압축)보다 1/10 이하로 압축할 수 있다.
4-6. 동영상 & 오디오 압축 : MPEG & MP3
MPEG는 Motion Picture Expert Graphics로써 동영상에서 일부 프레임만 전체를 인코딩하고 나머지는
차등인코딩 방식을 쓴다.
동영상과 오디오의 표준이다.
MP3는 (MPEG Audio Layer 3)
청각기관에서 인식할수 없는 미세한 정보를 버리는 방식으로 압축한다.
5. 데이터 오류 방지
데이터 저장 / 외부 전달 / 내부 연산 하는 과정에서 저장된 데이터의 일부가 손실될 수 있다.
이것을 방지하는 기법을 알아보겠다.
5-1. 패리티 비트 (Parity bit)
패리티는 홀짝성이라는 뜻인데 말 그대로,
비트 전체의 1의 개수를 홀수 아니면 짝수개로 만들어 놓고
전달 후의 비트의 개수가 전달 전과 동일한지 확인하면서 오류를 검사하는 기법이다.
전달할 비트의 맨 앞에 패리티 비트를 붙이는데 이것으로 홀수(짝수)를 만든다.
예를들어, 본래 데이터가 000이고 홀수로 만들 생각이라면 1000이 된다.
본래 데이터가 001이고 홀수로 만들 생각이라 0001이 된다.
단점은 오류가 발생할때, 홀수(짝수)개 만큼 오류가 뜨면 오류를 검사하지 못한다.
5-2. 검사합 오류 탐지 방지법
원본 데이터와 검사합을 합산하고 캐리니블을 버렸을때, 0x00이 나오는지 확인 하는 것으로 오류를 탐지하는 방법이다.
검사합은 원본 데이터에 2의 보수를 취하는 것으로 구한다.
캐리니블은 계산 결과의 최상위 니블을 말한다.
니블은 4비트 단위를 말한다.
예를들어 11을 보내야하면 검사합은 01이 된다.
이렇게 11과 01을 송신하면, 수신측은 11과 01을 더해서 100을 갖는다.
이때, 최상위 니블을 버려서 (실제론 4비트인데 예만 4비트가 아니라 1만 버리면 된다.) 00이 되므로 올바르게 송신이 됐음을 확인 할 수 있다.
'Computer Architecture' 카테고리의 다른 글
| 컴퓨터 시스템 개론 : 5장 : 알고리즘 (1) | 2024.04.27 |
|---|---|
| 컴퓨터 시스템 개론 : 4장 : 네트워크와 인터넷 (1) | 2024.04.27 |
| 컴퓨터 시스템 개론 : 3장 : 운영체제 (1) | 2024.04.26 |
| 컴퓨터 시스템 개론 : 2장 : 데이터의 조작 (0) | 2024.04.21 |
| OPCODE + ADDRESS : 16진수 4자리를 이용한 기계어 표현법 (0) | 2024.03.28 |




댓글